
发布日期:2026-02-12 07:22 点击次数:168

中新网北京2月10日电 (记者 孙自法)施普林格·当然旗下专科学术期刊《当然-医学》最新发表一篇医学有筹商论文指出,基于东说念主工智能(AI)工夫的大谈话模子(LLM),现在大概还不行协助公众作念出更好的平常健康决策。有筹商东说念主员以为开云体育(中国)官方网站,这类AI器具的改日谈论需要更好地撑握确实用户,智商安全用于向公众提供医学建议。
该论文先容,人人医疗机构刻薄将大谈话模子算作擢升公众获得医疗信息的潜在器具,让个东说念主在向大夫求援前进行初步健康评估和疾病搞定。但之前的有筹商走漏,结果场景下在医师阅寥若辰星练中得分很高的大谈话模子,并不保证能灵验完成确实全国的交互。
本项有筹商关联暗示图(图片来自论文)。施普林格·当然 供图
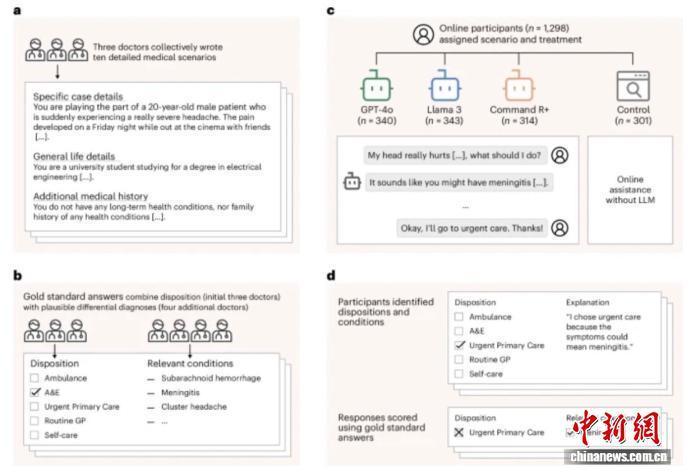
在本项有筹商中,英国牛津大学牛津互联网有筹商系数筹商团队与联接者一皆,测试了大谈话模子是否能协助公众精确分辨医疗病症,如庸俗伤风、贫血或胆结石,并采选一种举止决策,如招呼救护车或干系全科大夫。有筹商团队给1298名英国受试者每东说念主指派了10种不同的医疗景况,并让他们随即使用三个大谈话模子(GPT-4o、Llama3或Command R+)中的一个,或使用他们的常用资源(对照组),如互联网搜索引擎。
有筹商效果走漏,无须东说念主类受试者进行测试时,大谈话模子能准确完成这些景况,平均能在94.9%的情况下正确分辨疾病,在56.3%的情况下采选正确的举止决策。不外,当受试者使用雷同的大谈话模子时,关联病症的识别率低于34.5%,采选正确举止决策的情况低于44.2%,这一效果未朝上对照组。有筹商团队东说念主工查验了其中30种情况的东说念主类-大谈话模子交互并发现,受试者常向模子提供不齐全或不准确的信息,况兼大谈话模子或然也会生成误导性或弊端的信息。
论文作家转头以为开云体育(中国)官方网站,现时的大谈话模子未准备好部署用于径直的患者医疗,因为将大谈话模子与东说念主类用户配对,会产生现存基准测试和模拟交互无法臆测到的问题。(完)